近日,计算机学院彭玺教授及合作者在International Journal of Computer Vision (IJCV)及International Conference on Learning Representations(ICLR)上发表三篇论文,其中一篇论文入选ICLR Oral。IJCV是计算机视觉领域公认国际顶级期刊,是CCF-A类推荐期刊,最新影响因子为19.5。ICLR是机器学习领域的国际重要会议,在Google学术计算机科学领域中排行第3。ICLR2024共计收到7262篇投稿,录用率约为31%,其中Oral论文仅85篇,录用率约1.2%。
2022级博士研究生杨谋星为第一作者,彭玺教授为通讯作者,录用的IJCV论文“Robust Object Re-identification with Coupled Noisy Labels”指出了目标重识别任务中潜在的“耦合噪声标签”问题——样本身份标注错误导致模型训练过程中同时面临样本噪声标签和成对样本噪声关联的双重挑战,并提出相应解决方案。
2022级博士研究生杨谋星为第一作者,彭玺教授为通讯作者,录用的ICLR论文“Test-time Adaption against Multi-modal Reliability Bias”指出了测试时领域适应面临的模态可靠性偏置问题——多模态预训练模型在推理阶段时如何克服场景动态、传感器退化等领域漂移导致的模态间任务信息量不一致的挑战。
2020级直博研究生林义杰为第一作者,彭玺教授为通讯作者,录用的ICLR Oral论文“Multi-granularity Correspondence Learning from Long-term Noisy Videos”指出视频-文本预训练中面临多粒度噪声关联挑战,并通过最优传输算法显著降低噪声影响并节省了长视频训练开销。
论文1:Robust Object Re-identification with Coupled Noisy Labels
背景:给定目标图像,目标重识别(Object Re-identification, ReID)旨在从数据库中探查同一目标在其他场景下的图像,以达到对指定目标的搜索、轨迹溯源等目的,在智能安防中起到重要作用。根据应用场景和需求的不同,目标重识别包含许多子任务,其中常见的有:可见光行人重识别、跨模态(可见光-红外)行人重识别、车辆重识别。目前,主流的目标重识别范式训练过程中旨在从标注样本中种进行样本级的判别学习(Sample-wise Discrimination Learning)和从成对样本中进行成对级别的相似性学习(Pair-wise Similarity Learning)。其中,成对样本的关联关系需基于样本的身份标注进行构建,即:将相同身份的样本作为正样本对,不同身份的样本作为负样本对。

图1 目标重识别示例
尽管目前的目标重识别技术在各种场景中取得了很好的性能,目前的方案高度依赖于精准标注的数据。然而,开放环境下的真实目标数据标注困难。如图2所示,实际场景下往往存在图像分辨率低、光线弱、遮挡等问题,导致人为标注不准确,甚至出现错误。错误的样本身份标注(NoisyAnnotation)将导致所构建样本对的关联同时出现错误(NoisyCorrespondence),最终影响样本级别判别学习和样本对级别相似性学习。我们将这种特殊的问题称为耦合噪声标签问题(Coupled Noisy Labels)。因此,有必要研究能对耦合噪声标签鲁棒的目标重识别方法,以支持目标重识别算法落地开放环境。
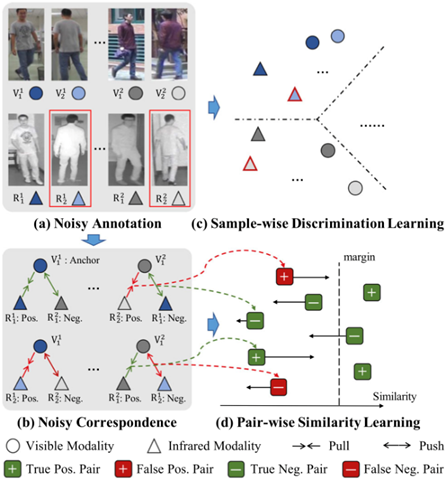
图2 耦合噪声标签问题示意图
不失一般性,以跨模态行人重识别为例,红框中的两个样本(R21和R22)由于姿势相似且光线弱、识别度低等原因,他们的身份被混淆,R11和R21、R12和R22分别被错误标注为相同身份。一方面,身份标注错误的样本将导致样本级别判别学习得到错误的决策边界;另一方面,随之而来的假阴性样本对(FalsePositive Pair)和假阳性样本对(False Negative Pair)即噪声关联(NoisyCorrespondence)将破坏模型的样本对相似性学习效果。
创新:一方面,本论文揭示了目标重识别中被忽略的重要问题——耦合噪声标签(Coupled Noisy Labels, CNL)。与传统的噪声标签问题不同,耦合噪声标签指代噪声身份标签(NoisyAnnotation)及其所带来的噪声关联(NoisyCorrespondence)。需要说明的是,难以通过仅克服噪声标签的影响来解决耦合噪声标签问题。具体而言,ReID数据集通常由数千个个体身份(类别)组成,这使得对噪声标签的准确校正几乎不可能。不准确的噪声标签校正仍然会引入噪声关联,最终降低模型性能。我们在论文的实验中验证了我们的观点。
另一方面,为解决耦合噪声标签问题,本文提出了一种名为LCNL的鲁棒目标重识别新框架(图3)。所提出的LCNL框架可以直接适配并应用在大多数现有的可见光行人重识别/跨模态行人重识别/车辆重识别方法中,赋予这些方法对耦合噪声标签的鲁棒性。

图3 LCNL算法框架图
实验:本文在三种主流的重识别任务,即可见光行人重识别(VisibleReID)、跨模态行人重识别(Visible-infrared ReID)、车辆重识别(VehicleReID)中的五个真实数据集上以一套统一且固定的超参数验证了LCNL的有效性。
论文2:Test-time Adaption against Multi-modal Reliability Bias
背景:神经网络模型的成功依赖于训练与测试数据的独立同分布假设。但实际应用中,测试数据的分布很容易偏离原始训练数据的分布(distribution shift),例如在采集测试数据的时候:1)恶劣气候使得图像中包含有雨、雪、雾的遮挡;2)拍摄高速运动物体时图像模糊,或传感器退化引入的噪声;3)模型基于城市A采集数据进行训练,却被部署到了城市B。神经网络模型在这些场景下其性能可能会大幅下降,制约了其在现实世界中的广泛部署。
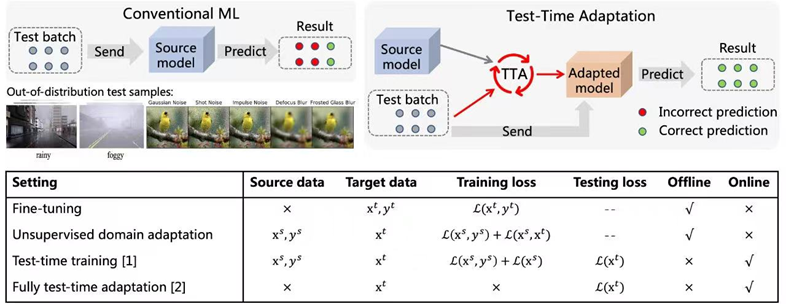
图1 Test-Time Adaptation示意图及其与现有方法特点对比
测试时领域适应(Test-time Adaptation,TTA)旨在使源域模型适应推理阶段时不同分布类型的测试数据。如图1所示,当测试数据流到来后,TTA范式首先基于该数据利用自监督或无监督的方式对源域模型进行微调,而后再使用更新后的模型做出最终预测。相较于传统的Fine-Tuning以及Unsupervised Domain Adaptation方法,Test-Time Adaptation可以针对任意预训练模型进行在线迁移,无需原始训练数据也无需干涉模型原始的训练过程,效率更高也更加普适。
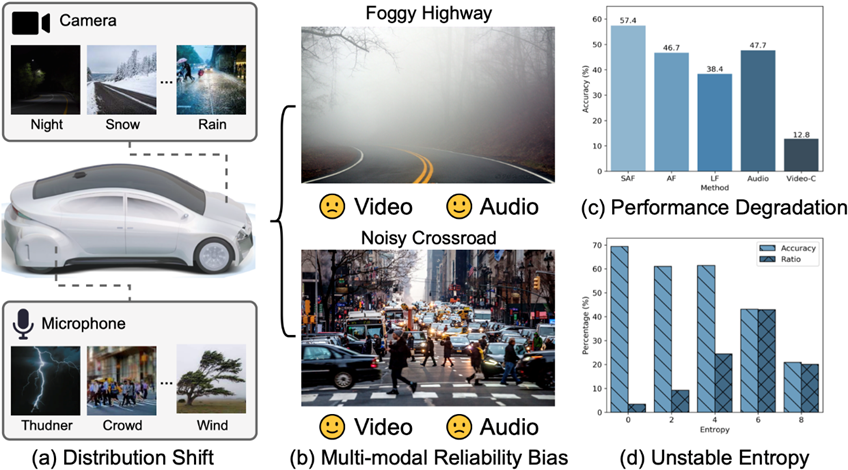
图2 模态可靠性偏置的观察。图中数据来自于Kinetics多模态数据集中测试数据流视觉模态偏置下得到的实验结果
尽管这些TTA是当前用于提高神经网络模型分布外泛化能力的有效范式,但大多数TTA方法都仅针对单模态测试数据的分布偏移,忽略了多模态场景的特殊性。具体的,一旦某个模态数据受到分布偏移的影响(图2-a),模态之间的任务信息差异将被放大,导致模态间的可靠性偏置。如图2-b的例子所示,当一辆搭载声学和视觉传感器的无人汽车行驶至嘈杂环境下视觉传感器将比声学传感器更可靠,行驶至雾天环境下则反之。上述情景下,将有某一模态出现分布偏移,进而引发模态可靠性偏置挑战。如图2-c所示,在该问题下,无论是经典的后期融合(LateFusion,LF)还是目前的主流基于注意力机制融合(Attention-based Fusion,AF)策略都将导致多模态模型性能严重退化。同时,目前面向不平衡多模态数据的方法要求在源域有标签数据中进行鲁棒训练,仅能缓解而无法从根本上解决该问题。
需要指出的是,现有TTA方法均无法有效处理这一挑战。一方面,现在TTA范式无法完全消除某个模态的分布偏移影响,不可避免引入模态可靠性偏置挑战,导致不可靠的多模态融合;另一方面,如图2-d所示,一旦代表性模态受分布偏移影响,只有少量低熵样本维持较高预测准确度,大量的预测结果呈现高熵且不准确现象,导致基于熵最小化的TTA方法严重欠/过拟合测试数据流。
创新:一方面,本文率先揭示了多模态TTA中的模态可靠性偏置问题。为促进对模态可靠性偏置问题的研究,本文以多模态行为识别和多模态事件分类为验证任务,提供了两个新的多模态可靠性偏置Benchmarks。
另一方面,本文提出一种名为REliable fusion and robust ADaptation (READ)的新方法。一方面,与现有TTA方法不同,READ使用了Self-adaptiveAttentionFusion (SAF)模块来动态调节模态之间的注意力,以此实现多模态测试数据流的可靠融合;另一方面,READ采用了一个鲁棒损失函数来实现噪声鲁棒的域自适应,该损失函数旨在减少噪声预测的影响同时增强干净预测的贡献。
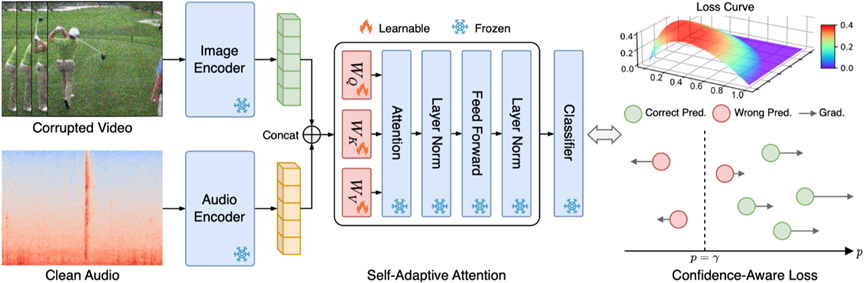
图3 Reliable fusion and robust adaptation方法的框架图
实验:本文旨在克服多模态TTA面临的模态可靠性偏置问题。我们以目前SOTA的视觉-声音预训练模型CAV-MAE为基础模型,通过多模态动作识别、多模态事件分类等具体任务上的15种视觉分布偏移和6种声学分布偏移类型进行验证。
论文3:Multi-granularity Correspondence Learning from Long-term Noisy Videos
背景:视频表征学习是多模态研究中最热门的问题之一。大规模视频-语言预训练已在多种视频理解任务中取得显著效果,例如视频检索、视觉问答、片段分割与定位等。目前大部分视频-语言预训练工作主要面向短视频的片段理解,忽略了长视频中存在的长时关联与依赖。长视频学习核心难点是如何去编码视频中的时序动态,目前的方案主要集中于设计定制化的视频网络编码器去捕捉长时依赖,但通常面临很大的资源开销。
由于长视频通常采用自动语言识别(ASR)得到相应的文本字幕,整个视频所对应的文本段落(Paragraph)可根据ASR文本时间戳切分为多个短的文本标题(Caption),同时长视频(Video)可相应切分为多个视频片段(Clip)。对视频片段与标题进行后期融合或对齐的策略相比直接编码整个视频更为高效,是长时时序关联学习的一种优选方案。然而,视频片段与文本句子间广泛存在噪声关联现象(Noisycorrespondence,NC),即视频内容与文本语料错误地对应/关联在一起。如图1所示,视频与文本间会存在多粒度的噪声关联问题。
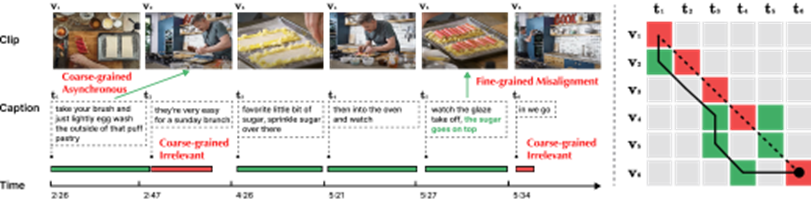
图1多粒度噪声关联。
该示例中视频内容根据文本标题切分为6块。(左图)绿色时间线指示该文本可与视频内容对齐,红色时间线则指示该文本无法与整个视频中的内容对齐。t5中的绿色文本表示与视频内容v5有关联的部分。(右图)虚线表示原本给定的对齐关系,红色指示原本对齐中错误的对齐关系,绿色则指示真实的对齐关系。实线表示通过DynamicTimeWraping算法进行重新对齐的结果,其也未能很好地处理噪声关联挑战。
●粗粒度NC(Clip-Caption间)。粗粒度NC包括异步(Asynchronous)和不相关(Irrelevant)两类,区别在于该视频片段或标题能否与现有标题或视频片段相对应。其中“异步”指视频片段与标题间存在时序上的错位,例如图1中t1。由于讲述者在实际执行动作的前后进行解释,导致陈述与行动的顺序不匹配。“不相关”则指无法与视频片段对齐的无意义标题(例如t2和t6),或是无关的视频片段。根据牛津Visual Geometry Group的相关研究,HowTo100M数据集中只有约30%的视频片段与标题在视觉上是可对齐的,而仅有15%是原本就对齐的;
●细粒度NC(Frame-Word间)。针对一个视频片段,可能一句文本描述中只有部分文字与其相关。在图1中,标题t5中“糖撒在上面”与视觉内容v5强相关,但动作“观察釉面脱落”则与视觉内容并不相关。无关的单词或视频帧可能会阻碍关键信息提取,从而影响片段与标题间的对齐。
创新:本文提出噪声鲁棒的时序最优传输(NOise Robust Temporal Optimal transport, Norton),通过视频-段落级对比学习与片段-标题级对比学习,以后期融合的方式从多个粒度学习鲁棒视频表征,显著降低了训练时间开销。
总结:彭玺教授组在NeurIPS2021Oral工作中针对跨模态匹配问题,基于对真实数据集Conceptual Captions的观察,揭示了假阳性的错误配对现象,首次正式提出了噪声关联学习的概念和方向。课题组进一步探索实际场景中存在的模态非完备问题,揭示了视频数据字幕与画面间的多粒度噪声关联问题、目标重识别中的耦合噪声问题、以及多模态测试时领域适应中的模态可靠性偏置问题,拓宽真实场景下模态非完备的外沿。

