近日,我校计算机学院彭玺教授课题组在Neural Information Processing Systems(NeurIPS)上发表四篇论文,其中三篇为其指导的研究生完成。NeurIPS是机器学习领域的国际顶级会议,是CCF A类推荐会议。
彭玺教授指导的2023级硕士研究生刘泓麟为第一作者,录用的论文“Interactive Deep Clustering via Value Mining”[1]在国际上首次提出在深度聚类过程中引入用户交互,以较小的交互成本,对现有聚类方法面临的难样本进行辨别与纠正,从而突破了内部驱动的聚类方法固有的性能瓶颈。
彭玺教授指导的2023级直博研究生郭睿明为第一作者,录用的论文“Robust Contrastive Multi-view Clustering against Dual Noisy Correspondence”[2]针对数据中的双重噪声关联,提出了基于上下文和谱分析的聚类方法,显著提升了多视图聚类在双重噪声关联下的鲁棒性。
彭玺教授指导的2022级直博研究生赵海宇为第一作者,录用的论文“AverNet: All-in-one Video Restoration for Time-varying Unknown Degradations”[3]在国际上首次研究了多合一视频复原问题,旨在通过单个模型处理视频中噪声、模糊等随时间变化且类型未知的退化,为处理真实世界中多变的视频退化提供了思路。
论文1:Interactive Deep Clustering via Value Mining [1]
背景:深度聚类旨在按照语义将样本划分至不同的类簇。现有内部驱动的聚类方法大都注重于挖掘样本自身有限的语义信息,其性能最终受限于数据自身固有的信息量。其中,内部驱动聚类方法的一大性能瓶颈在于其对类簇边界的样本难以准确区分。因此,引入合适的外部知识来辨别并纠正难样本,能够有效地提升性能,促进深度聚类算法在现实生活中的落地应用。
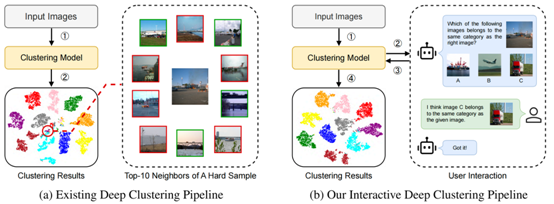
图1:现有内部驱动的聚类方法与本文提出的交互式聚类方法的比较。(a)现有内部驱动的聚类方法对难样本的区分度较差。以图中红圈内的一个难样本为例,该样本图片与邻居在视觉上相似,难以被聚类方法区分,然而其实际语义差距较大,进而导致了聚类性能瓶颈。(b)本文提出的交互式聚类方法,通过用户交互的方式对难样本进行辨别与纠正,从而突破内部驱动的聚类方法固有的性能瓶颈。
方法:针对内部驱动的聚类方法所面临的难样本问题,本文提出了一种基于价值挖掘的交互式聚类方法(IDC),通过用户交互的方式,对难样本进行有效的辨别与纠正,从而改善深度聚类性能。交互式聚类方法面临两个挑战:(1)如何设计高效且用户友好的交互方式;(2)如何有效利用用户反馈来改善聚类结果。
具体地,针对挑战(1),给定一个预训练的聚类模型,IDC首先提出了一个衡量样本价值的标准,从困难度、代表性和多样性三个角度,挑选出高价值样本进行用户交互。对于每一个挑选出的样本,IDC要求用户判断该样本与其最近的若干个聚类中心的隶属关系。针对挑战(2),IDC基于用户正/负反馈,提出对应的正/负样本学习损失函数对聚类模型进行微调。此外,为了防止模型对交互的样本产生过拟合,IDC为预训练聚类模型的高置信度样本构建了一个规范化损失函数,避免原有的聚类边界被显著改变。
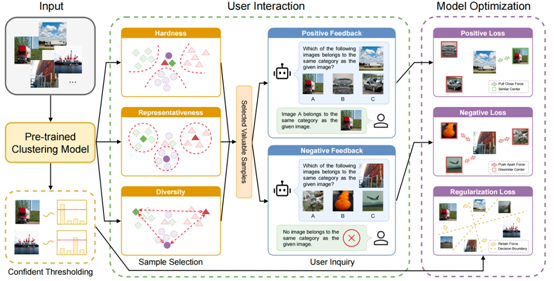
图2:所提出的IDC方法框架,包括用户交互和模型优化两个阶段。在用户交互阶段,对于给定的预训练聚类模型,从困难度、代表性和多样性三个角度,挑选出高价值样本进行用户交互,向用户询问所选样本相对于其最近的聚类中心的隶属关系。在模型优化阶段,依据用户的正/负反馈,使用相应的损失函数对聚类模型进行微调以优化聚类边界,同时对高置信度的样本采用规范化损失函数,来避免模型过拟合交互样本。
实验:本文在五个图像聚类数据集上对方法进行了验证,部分实验结果如下:
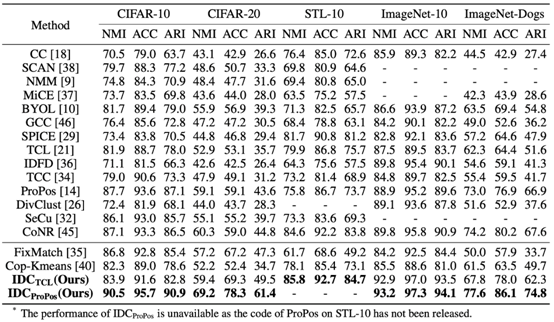
表1:所提出的IDC方法在经典图像聚类数据集上的聚类性能
从表中可以看出,IDC有效地改善了两个内部聚类方法(TCL[4]、ProPos[5])的预训练模型的性能,尤其是在较为困难的CIFAR-20和ImageNet-Dogs数据集上。同时,与现有的半监督分类和半监督聚类方法相比,IDC都取得了显著的性能优势,更多实验结果详见论文。
总结:与现有的绝大多数聚类方法只挖掘内部语义信息不同,本文提出了交互式深度聚类方法IDC,通过引入用户交互来解决现有聚类算法面临的难样本问题,是沿着此前团队在TAC[3]中提出的外部引导的聚类范式进行的一次全新的探索性工作。通过挖掘高价值样本和设计高效的交互方式,本方法通过较小的交互成本,显著地提升了聚类算法的性能,有效地促进了深度聚类算法在现实生活中的落地应用。
论文2:Robust Contrastive Multi-view Clustering against Dual Noisy Correspondence [2]
背景:目前,大量多模态数据获取于互联网等开放场景下,难以避免包含图文错配、文不对题、音画不同步等噪声关联现象。然而,现有多模态学习方法依赖于正确关联的多模态数据,上述噪声关联现象将严重影响多模态学习的性能。
在该工作中,我们聚焦于多视图聚类任务,其旨在无需依赖标注的情况下,将多模态实例依据语义划分到不同的类簇中。我们揭示了多视图聚类任务不可避免面临双重噪声关联问题。具体而言,双重噪声关联指代跨模态正例中存在的对齐错误(即假阳性关联)和跨模态负例中被忽略的语义相关性(即假阴性关联)。为此,本论文设计了双重噪声关联鲁棒的多视图聚类方法。
方法:本质上,双重噪声关联将导致多视图聚类过程中监督信号的错误。针对此,本工作提出了一种基于上下文和谱分析的关联精炼算法(CANDY,图3),其通过对跨模态上下文的建模和谱图理论来实现噪声监督信号的降熵增质,可适配目前大多数主流多视图聚类方法,赋予它们对双重噪声关联的鲁棒性。
具体而言:一方面,为降低假阴性关联的影响,本方法将样本的跨模态邻域信息(即上下文)作为样本新表征,基于此来探查与样本语义相关但却被错误作为负例的假阴性关联。相较于此前基于样本相似性的低阶探查方法,本方法从样本-样本关系出发,这种高阶相似性计算方法能挖掘更多潜在的假阴性关联;另一方面,本工作发现跨模态样本相似性图中较小奇异值的成分有更大概率对应假阳性关联,基于此提出了面向假阳性关联的相似性图去噪方法,有效缓解了假阳性关联的负面影响。
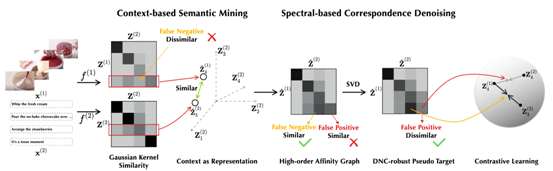
图3:所提出的CANDY方法框架。首先,使用各视图独立的编码器提取数据的表征,利用该表征构造模态内和模态间的相似性图。之后,基于样本的跨模态高阶相似性,探查样本中的假阴性关联,并利用相似性图去噪方法,缓解假阳性关联的负面影响,实现监督信号的降熵增质。最后,基于该监督信号实现对双重噪声关联的鲁棒多模态对比聚类。
实验:本文在五个经典数据集上验证了所提出方法的有效性,部分结果如下:
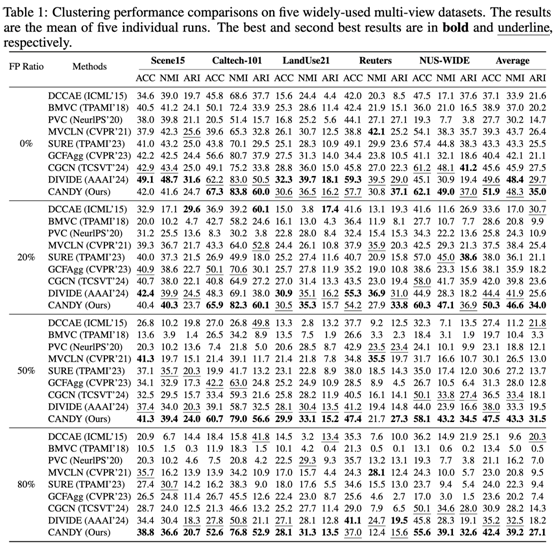
表1:所提出的CANDY方法在不同噪声率下的多视图聚类数据集上的聚类性能
从实验结果可以看出,相比现有方法,本方法在被双重噪声关联污染的数据集上取得了显著的性能提升,表明了本方法对双重噪声关联的鲁棒性。
论文3:AverNet: All-in-one Video Restoration for Time-varying Unknown Degradations [3]
背景:视频复原旨在去除低质量视频中的退化(如噪声、模糊和伪影),恢复视频的纹理细节,改善视觉效果。近年来,视频复原方法取得了显著进展,能够完成各种各样的视频复原任务,如去噪、去模糊和去压缩伪影。尽管这些方法取得了不错的性能,但其假设了视频中的退化类型是已知且固定的。然而,这种假设在实际应用中并不适用,因为视频中的退化会随相机移动、场景切换而发生变化,且类型繁杂、难以鉴别。因此,研究一种能自适应处理随时间变化且类型未知退化的多合一视频复原方法,对真实场景中的视频复原具有重要意义。
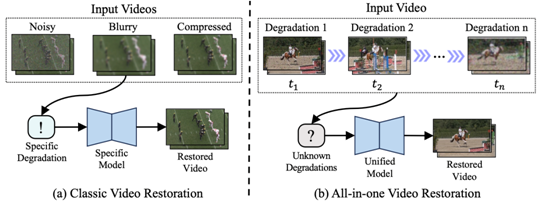
图1:传统视频复原方法和多合一视频复原方法的示意图。(a)传统视频复原方法旨在为每种退化类型开发一个特定的模型来处理受损视频,其假设所有帧的退化类型和受损程度都是相同且已知的。(b)本文提出的多合一视频复原方法,旨在通过一个统一模型处理随时间变化且类型未知的退化,其更具实用性和挑战性。
方法:为了应对视频中随时间变化且类型未知的退化(TUD),本文提出了多合一视频复原网络AverNet,其自适应学习指明退化类型的提示,并在提示信息的引导下处理变化且未知的退化。具体地,AverNet包括两个核心模块:提示引导的对齐模块(PGA)和基于提示的增强模块(PCE)。其中PGA用于解决由时间变化退化导致的视频帧错误对齐问题,通过学习并利用提示信息实现像素级别的帧对齐。而PCE则将处理多种未知退化的问题转换为条件复原问题,通过构建退化与干净图像之间的隐式条件映射来处理不同类型的退化。通过这两个模块的相互协作,AverNet可以有效处理视频中随时间变化且类型未知的退化,能够在复杂且动态变化的场景中实现高效的视频复原。
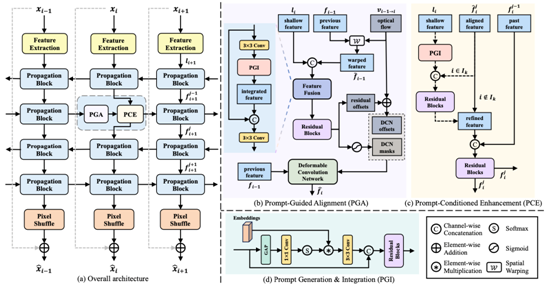
图2:所提出方法的架构概述。(a)AverNet网络的整体架构,其主要由传播模块组成。每个传播模块包括一个(b) PGA模块,用于在时间变化的退化中对帧间特征进行空间对齐,以及一个(c) PCE模块,用于增强当前帧的未知退化特征。(d) PGI模块通过基于输入的条件提示赋予PGA和PCE根据提示进行自适应处理的能力。为了简化,(b)中省略了上标j。在(c)中,past feature指的是上次传播中的特征。
实验:本文在多种退化变化频率、多种退化组合测试集上验证了方法在处理变化且未知退化的有效性,部分实验结果如下:
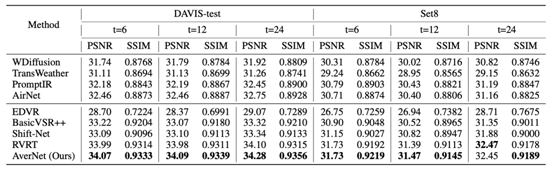
表1:所提出的AverNet方法在退化变化测试集上的复原结果
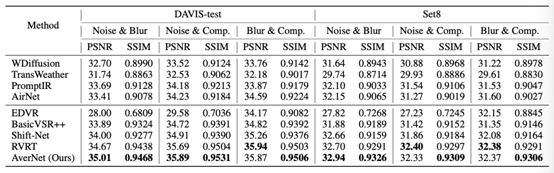
表2:所提出的AverNet方法在不同组合退化测试集上的复原结果
从表中可以看出,AverNet在处理变化且未知退化方面表现突出。在基于DAVIS-test和Set8合成的多个包含变化退化的测试集上,AverNet相比传统视频复原方法(如EDVR[6],BasicVSR++[7])的恢复效果更佳,在PSNR和SSIM指标上取得了更高的分数。更多实验结果请参考论文。
总结:不同于现有针对已知固定退化设计的视频复原方法,本文首次探讨了视频中变化且未知退化的问题,并提出了一种多合一视频复原模型。所提出的模型能够以单一模型自适应去除视频中变化且类型未知的退化,相比于传统视频复原方法的性能更强,在真实场景中的实用性更好。
自2022年彭玺教授课题组在国际上率先提出多合一图像复原问题,该研究方向已成为影像复原和增强领域的近年来最受关注的新方向之一。面向变化且未知退化的多合一视频复原是彭玺教授课题组提出的多合一影像复原任务面向真实开放世界的进一步延伸和拓展,有望给视频处理领域提供新的洞见和理解。
参考文献:
[1]Liu H, et al. Interactive Deep Clustering via Value Mining, Neural Information Processing Systems (NeurIPS 2024), 2024.
[2] RGuo R., et al. Robust Contrastive Multi-view Clustering against Dual Noisy Correspondence, Neural Information Processing Systems (NeurIPS 2024), 2024.
[3] Zhao H, et al. AverNet: All-in-one Video Restoration for Time-varying Unknown Degradations, Neural Information Processing Systems (NeurIPS 2024), 2024.
[4] Li Y, et al. Twin contrastive learning for online clustering[J]. International Journal of Computer Vision, 2022, 130(9): 2205-2221.
[5] Huang Z, et al. Learning representation for clustering via prototype scattering and positive sampling[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(6): 7509-7524.
[6] Wang X, et al. EDVR: Video restoration with enhanced deformable convolutional networks[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2019: 0-0.
[7] Chan K, et al. Basicvsr++: Improving video super-resolution with enhanced propagation and alignment[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 5972-5981.

